A reinforcement-learning project
A chess engine that teaches itself
An AlphaZero-style reinforcement-learning system, built from scratch in Python & PyTorch — a neural network (policy + value) guided by Monte-Carlo Tree Search that learns purely by playing itself. This site showcases that project: read how it learns, watch it self-play, and play a game yourself.
Heads-up: so a game is enjoyable today, the live board's opponent is a fast classical engine. The reinforcement-learning network is the from-scratch learning project — see How it works.
Neural network
A residual CNN reads the board and outputs a move policy and a value (who's winning) — no hand-written chess knowledge.
Search (MCTS)
Monte-Carlo Tree Search with the PUCT rule looks ahead, turning the network's hunches into much stronger moves.
Self-play learning
The engine is its own opponent and its own teacher: games become training data, which sharpens the next generation.
Play it now
The live board uses a fast classical search so it plays sound chess today — captures, tactics and real checkmates.
How this is different from other chess engines
Most chess engines are pre-built black boxes. This one is about understanding how an engine learns and thinks.
It learns, it isn't told
Engines like Stockfish run on decades of human-tuned chess knowledge. This one starts from random and teaches itself — the AlphaZero idea — discovering good play from its own games.
It shows its thinking
See the live evaluation, win probability and the moves it's considering, drawn as arrows on the board. Most engines never let you see why.
Built from scratch to be understood
The network, the search and the self-play loop are all written from scratch and explained in plain English on the How it works page. It's a learning tool, not just a player.
Watch it play itself
Hit “Watch self-play” and the engine reasons through a whole game on its own — exactly the kind of self-play it learns from.
Game
Tip: right-click + drag to draw an arrow; right-click a square to mark it. Keys: N new · F flip · U undo · H hint.
Material
Evaluation
Engine recommends
Moves
How the engine works
The same three ideas that powered DeepMind's AlphaZero — implemented from scratch to be read and understood, not just run.
The simple version (30 seconds)
Nobody teaches the engine chess strategy. It only knows the rules. It gets good through one repeating loop:
- Guess. A neural network looks at the board and guesses the best moves and who's winning.
- Think. A search tries out those moves many moves deep to find something better than the first guess.
- Play itself. It plays thousands of games against itself using that search.
- Learn. Whoever won, it nudges the network toward the moves that led to wins — so next time the guess is already smarter.
Repeat millions of times and the engine bootstraps itself from random moves to real chess — with zero human strategy added. Everything below is just that loop, in detail.
1 · One network, two heads — the "guess"
A position is encoded as an 18 × 8 × 8 stack of planes (piece locations, castling rights, …), always shown from the side-to-move's perspective. A residual convolutional network maps it to:
- a policy — a probability over all
8×8×73 = 4672possible moves ("which moves look promising?"), and - a value in [−1, 1] — "who is winning?"
2 · Search that thinks ahead (MCTS + PUCT) — the "think"
Each move, hundreds of simulations descend a search tree, balancing what looks good now against what's worth exploring, using the PUCT rule:
Exploitation (Q, the average value found) plus exploration (the network's
prior P, damped by how often a move was tried). The most-visited move is the
search's verdict — far stronger than the raw network.
3 · The self-play loop — "play itself" & "learn"
The training objective combines both heads (plus weight decay):
value error (MSE to the game result z) + policy cross-entropy to the MCTS
target π. Minimising both is what makes a single network good at both
halves of the search.
4 · A real training run
Loss from an actual self-play run — the policy loss drops sharply as the network learns to imitate the search:
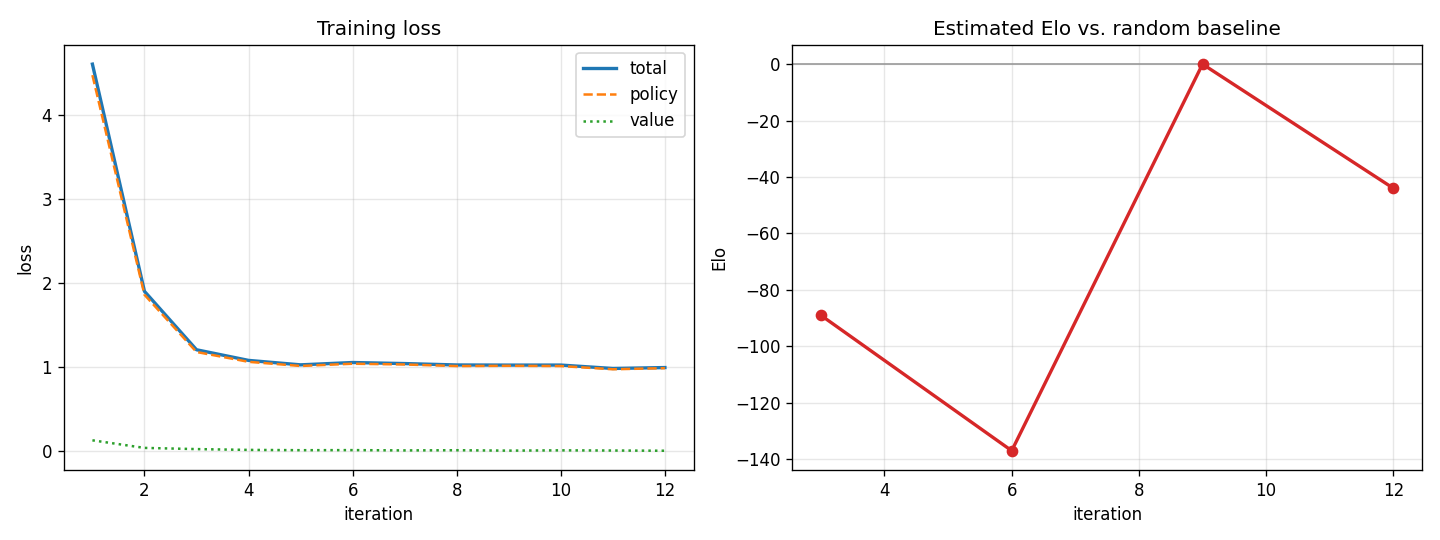
Honest note: reaching strong play needs far more (GPU) self-play than a laptop CPU allows — the learning machinery is correct, the limit is compute. So the live board above uses a fast classical alpha-beta engine (material + endgame heuristics, quiescence) that plays sound chess today, while the neural network remains the from-scratch learning project.